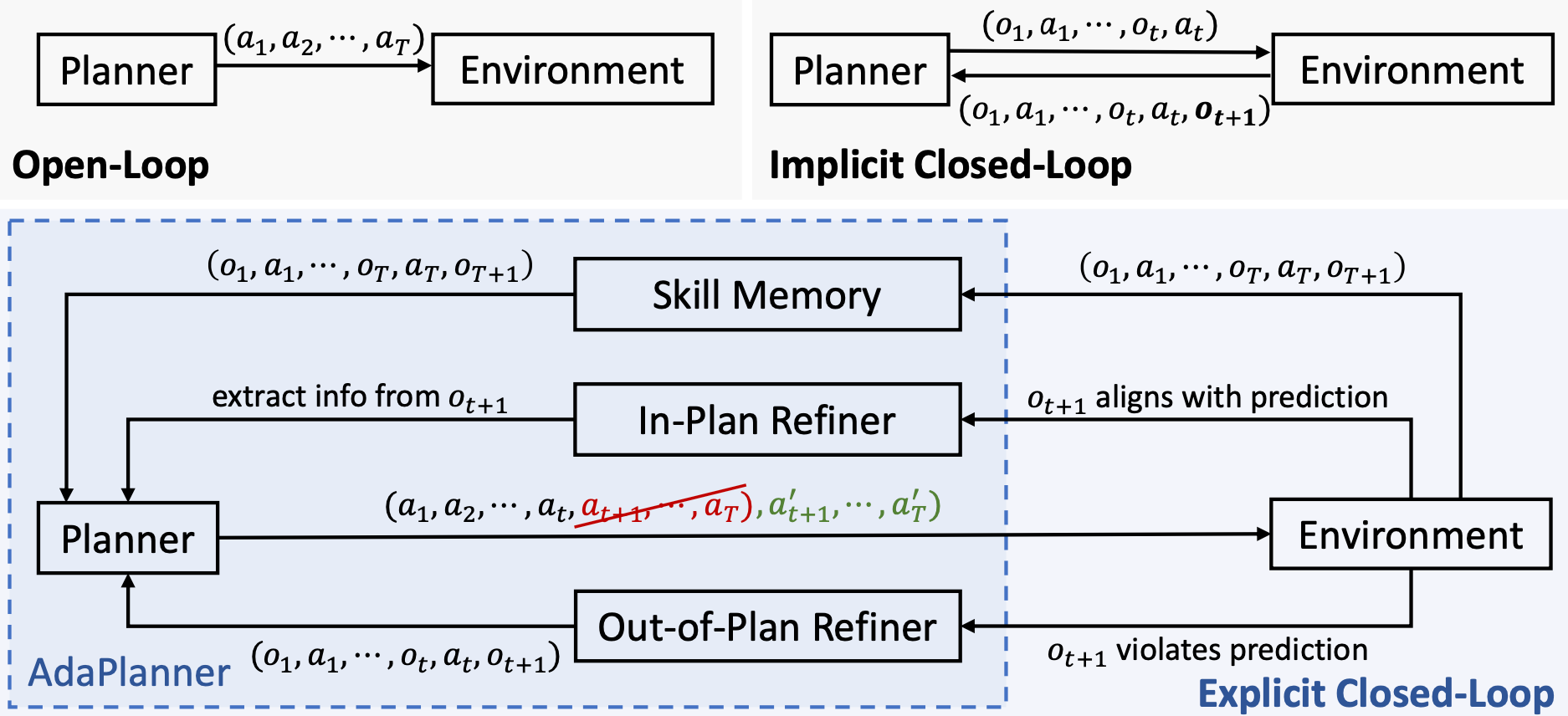
most existing methods either take actions greedily without planning or rely on static plans that are not adaptable to environmental feedback.
AdaPlanner allows the LLM agent to refine its self-generated plan adaptively in response to environmental feedback.
AdaPlanner adaptively refines its plan from feedback with both in-plan and out-of-plan refinement strategies.
a closed-loop planning method with LLM playing two roles: planner and refiner.
The planner decomposes the task into manageable sub-goals and predicts environmental feedback for each.
The refiner distinguishes and responds to two types of environment feedback.
in-plan feedback is the environmental observation that aligns with the prediction.
out-of-plan feedback is one that deviates from the prediction
For in-plan feedback, the refiner can dynamically query the LLM to perform reasoning and extract key information.
The LLM separately parses the observation and obtains information pertinent to subsequent actions.
For out-of-plan feedback, the refiner proactively revises the entire plan and resumes to solve the current task from an intermediate point.
initial planning policy ρ(P0∣g,o1):G×O→Δ(AT)
ρ(⋅∣g,ct,Pt) : high-level planning policy that generates an entire plan
π(⋅∣g,ct,Pt) : action-generation policy conditioned on a given plan Pt
Architecture
an LLM-based agent that functions dually as a planner and a plan refiner, and
a skill memory module designed to enhance sample efficiency through skill discovery.
In-plan refinement: one-step action; integrates useful information into the existing plan for better action grounding.
π(a>t′∣g,c>t∪{ht},P0)
Out-of-plan refinement: leverages environmental feedback to directly revise the entire plan.
ρ(Pt∣g,ct,Pt−1)
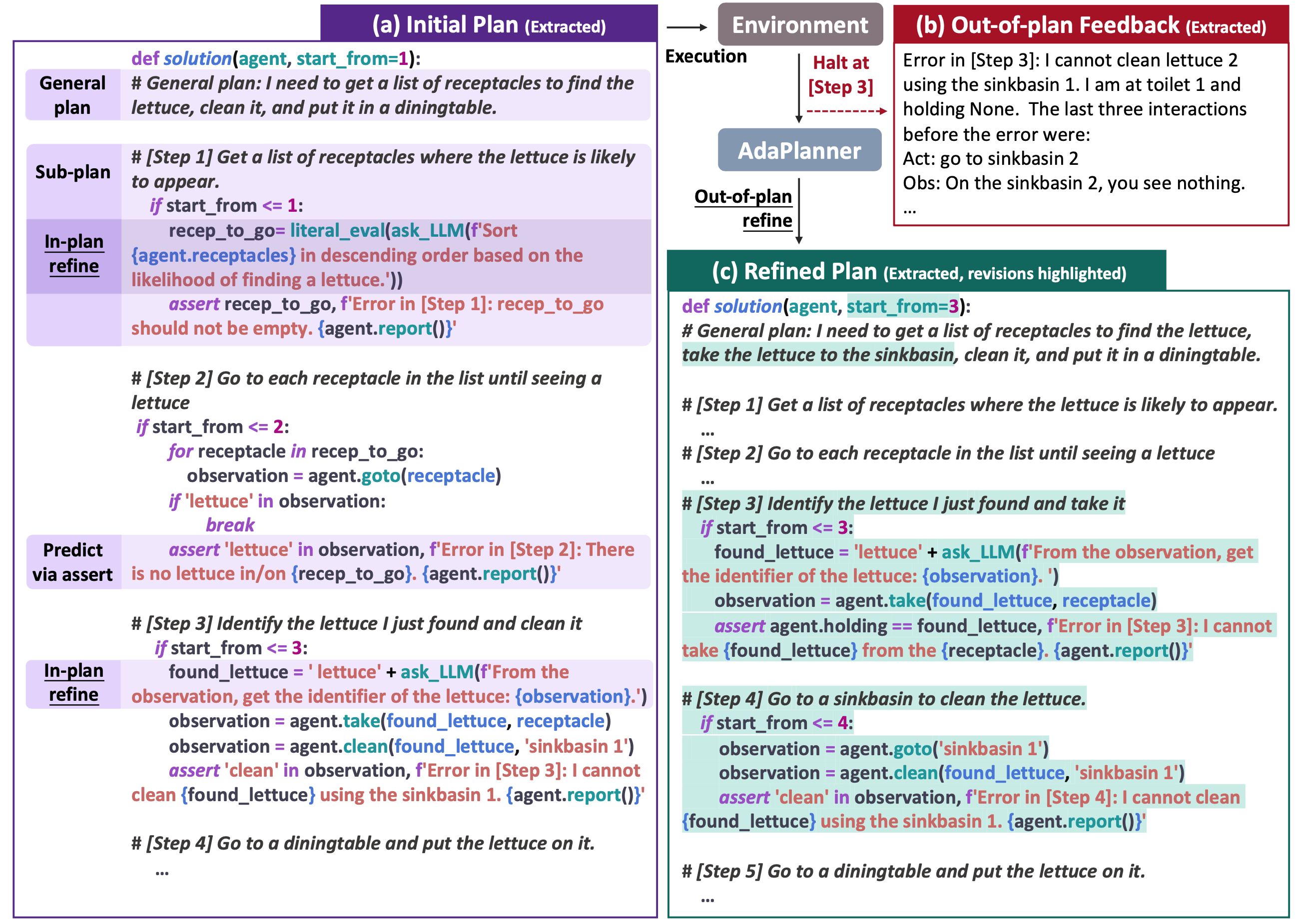
In-Plan Feedback and Refinement:
when AdaPlanner observes that the environment is aligned with the anticipated plan.
extract useful information from the observation that can be used for upcoming actions.
Out-of-Plan Refinement with the Refine-Then-Resume Mechanism:
If this condition is not met, AdaPlanner generates an error message that details the current progress of execution.
Skill Discovery
Equipped AdaPlanner with a skill discovery feature.
A memory scheme that discovers and archives successful trajectories, thereby improving planning performance when dealing with similar tasks.
Skill Acquisition. Upon successful completion of a given task, the latest solution and the corresponding interactions are treated as candidate discovered skills.
Skill Filtering. Compare the planning performance with and without the integration of the discovered solution into the prompt. If the inclusion of this solution boosts the success rate, it is archived as a discovered skill.
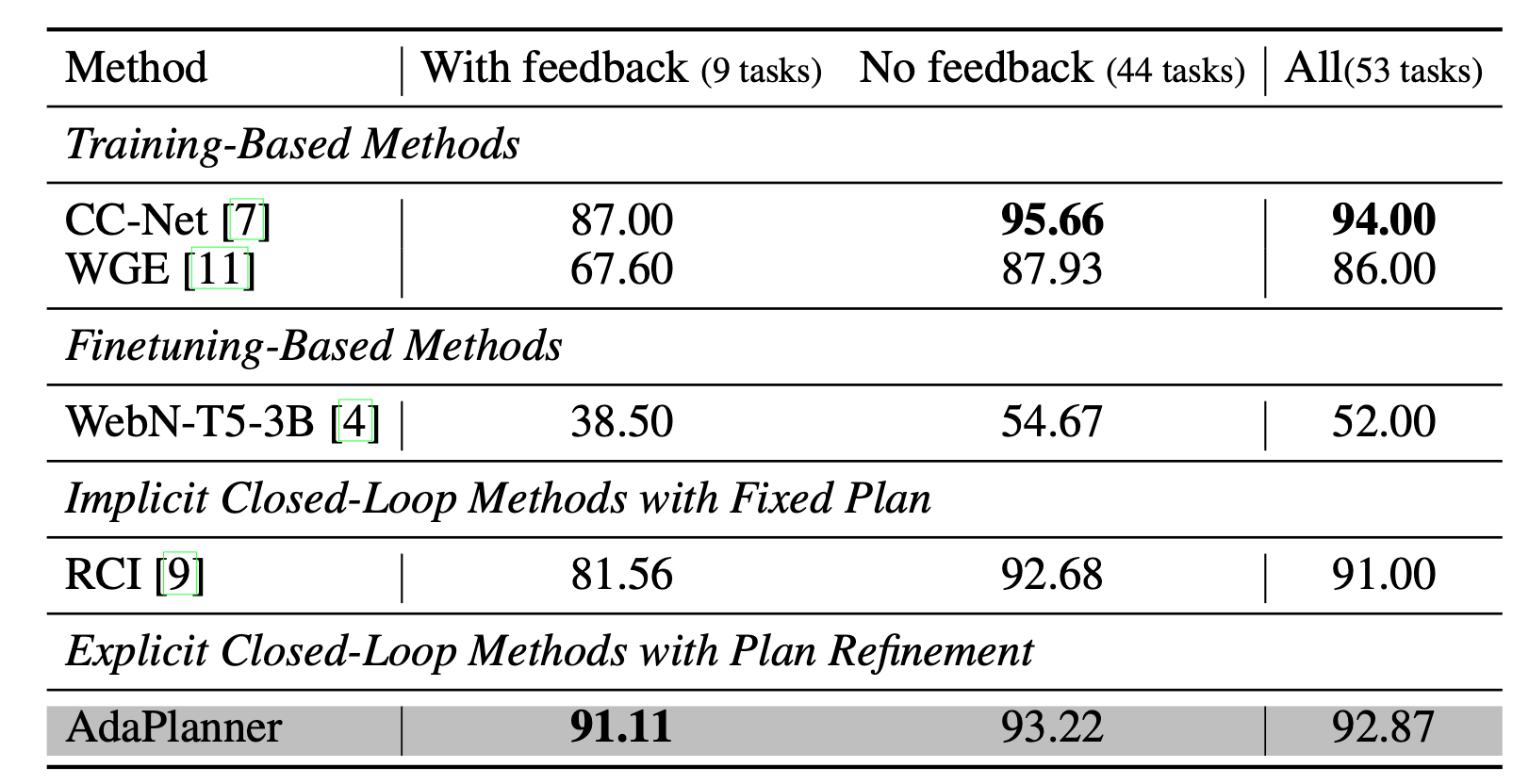
MiniWoB++: simulation environment that covers a large range of computer tasks.
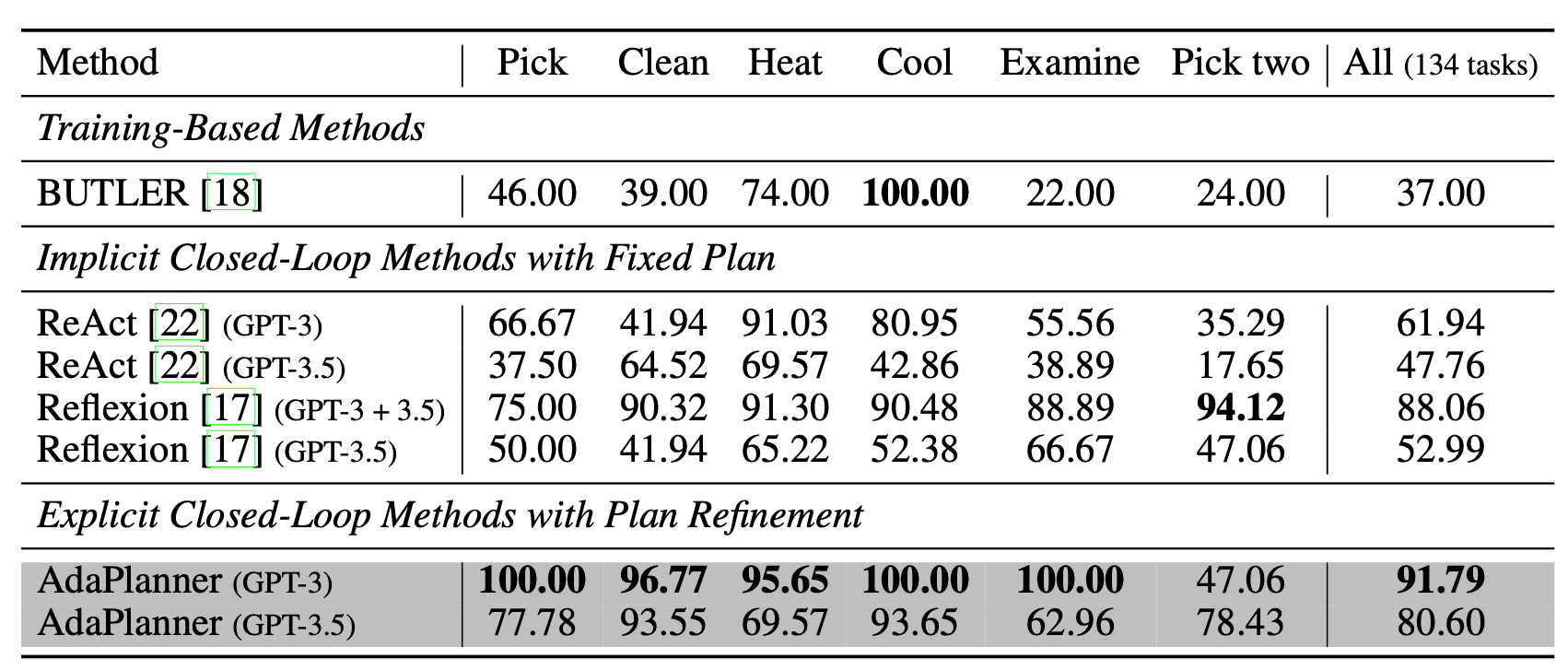
We observed a noticeable hallucination with GPT-3.5.
We hypothesize that gpt-3.5-turbo might be a smaller-scale model that is more prone to hallucination.
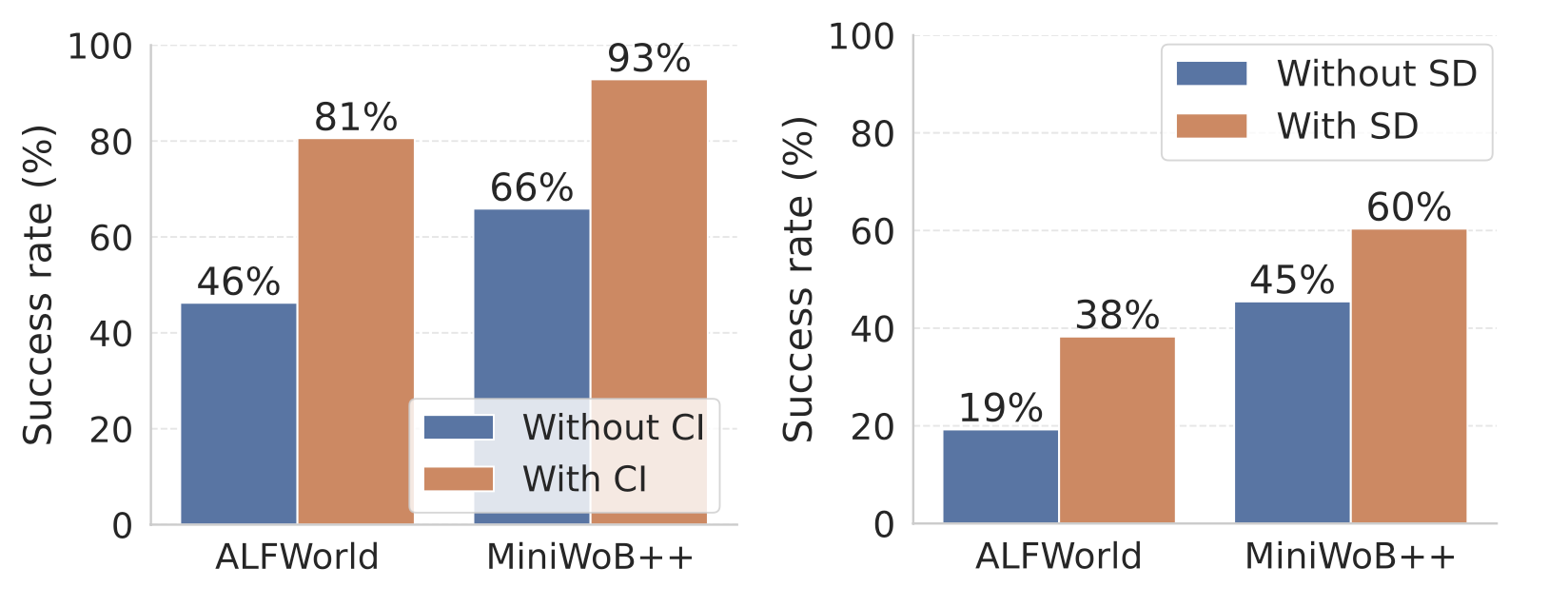
Without the code interface, AdaPlanner’s performance substantially drops in both ALFWorld and MiniWoB++ environments, from 81% to 46% and from 93% to 66%.
fine-tuned variants of a pre-trained model can all share an architecture but nevertheless are specialized to different tasks.
study the relationship between the weights of different fine-tuned models and the capabilities they exhibit.
In particular, we show that after a pre-trained model is fine-tuned on similar datasets, the resulting fine-tuned models are close to each other in the weight space.
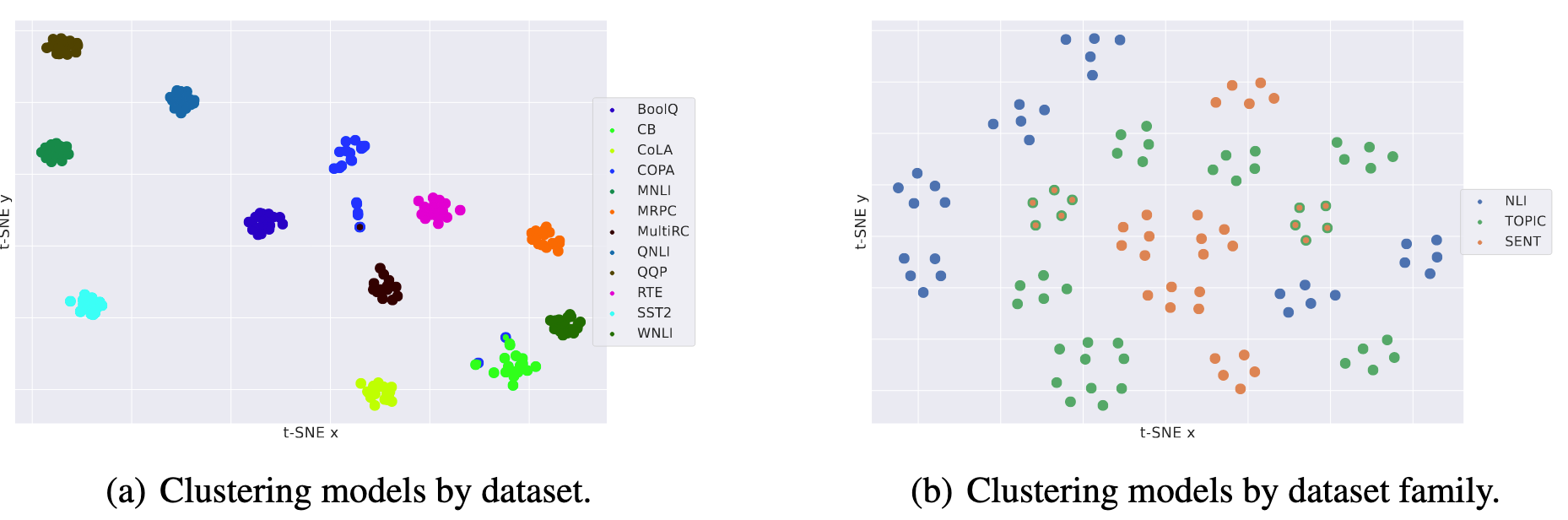
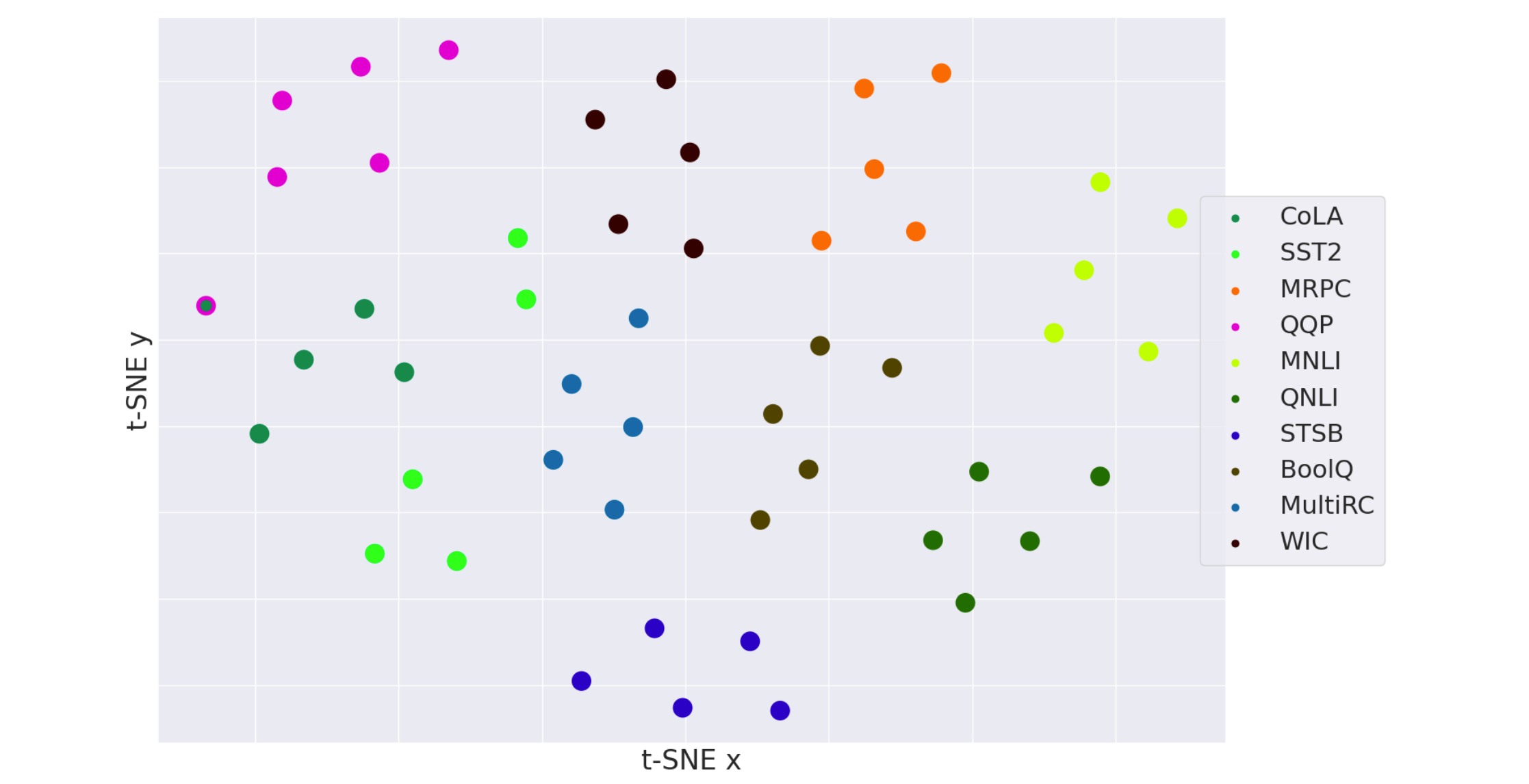
models fine-tuned on the same data are closer to each other than to other models.
models that were fine-tuned on the same task also cluster together.
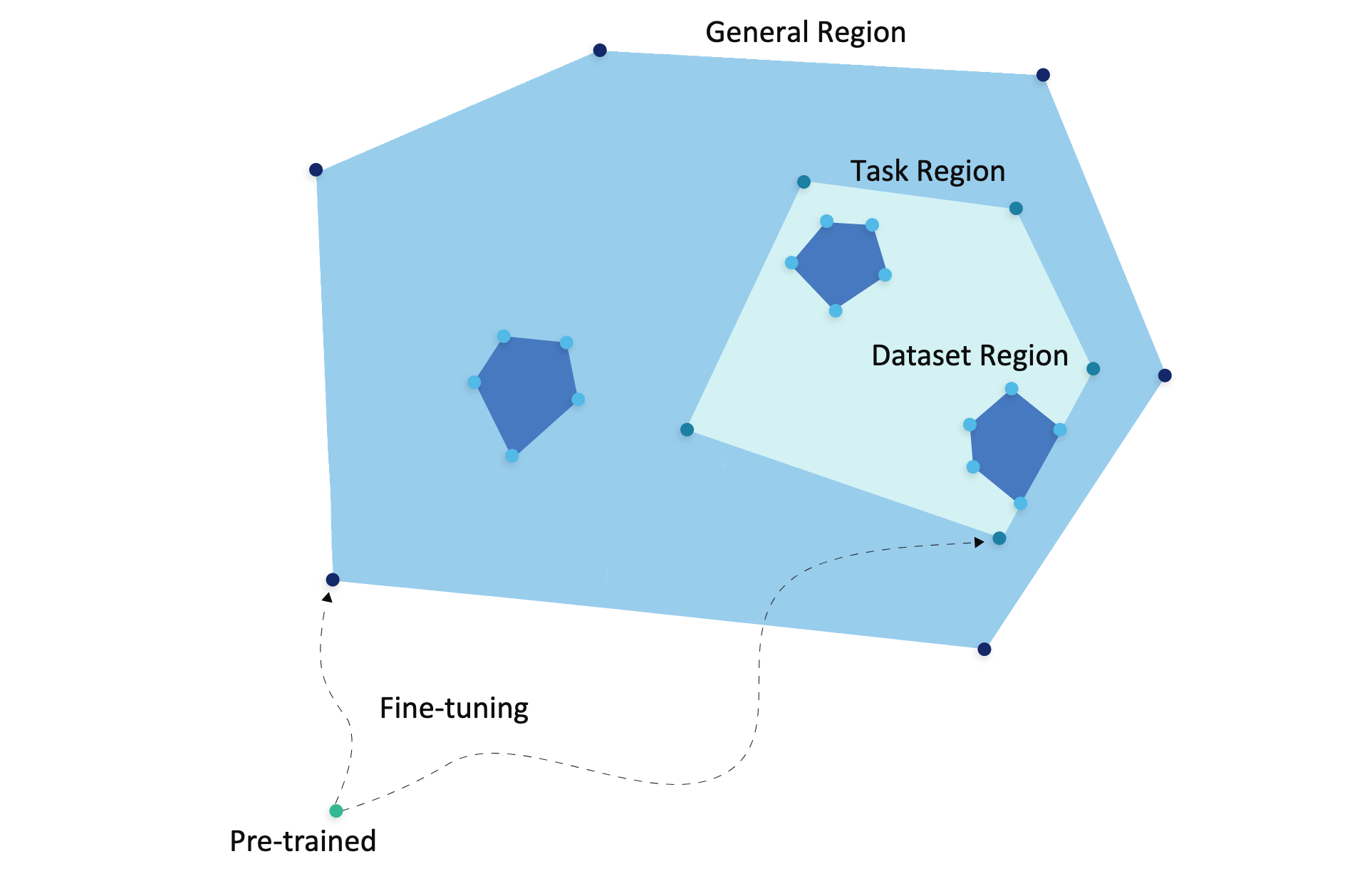
models fine-tuned on language tasks are not spread around the pre-trained space arbitrarily but rather correspond to a constrained region in weight space.
two main types of experiments.
train models with different dataset and task and examine their representation in weight space using clustering.
compare losses of one group of models to another.
we fine-tune and evaluate models on 36 datasets.
experiment with RoBERTa-base as our base pre-trained model.
Comparing Models
Our goal is to compare models that share an architecture but were trained on different data.
We would also be able to directly compare the loss achieved by these models.
fine-tuning on similar data yields models that are closer to each other in the weight space.
the fine-tuned model moves more with more data.
similar datasets go to similar direction even with different amount of data.
Loss in the Region between Models
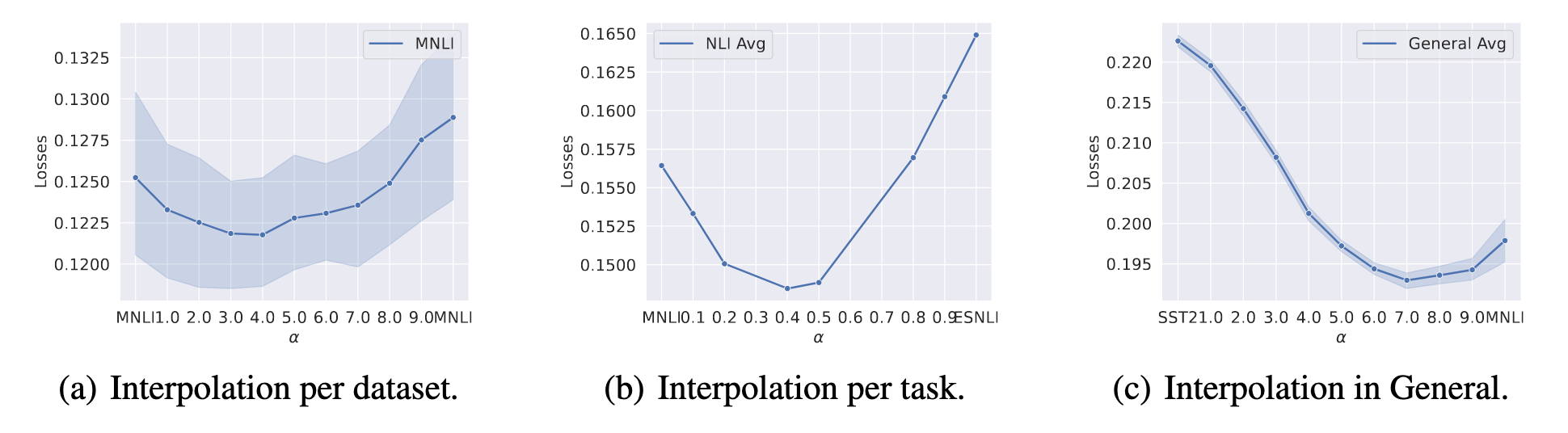
We hypothesize that a whole region of low losses exists between the separate points found during fine-tuning.
In order to test this hypothesis, we interpolate pairs of similarly trained models and show that the points between the models act comparably to or even better than the original fine-tuned models.
ω1∗α+ω2∗(1−α)
Thus far, we showed that models on the line between model pairs perform well.
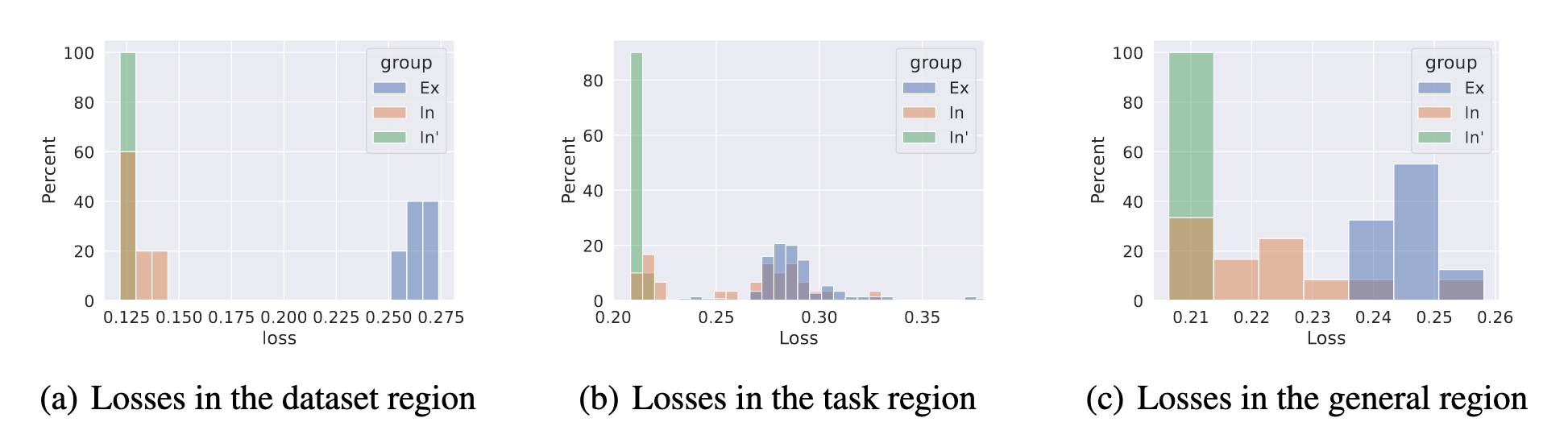
We now extend the analysis to show that models in the whole region.
calculate the probability that an interior model outperforms an exterior one: PB=i∈In,j∈ExE1{lg(ωi)≤lg(ωj)}.
convex hull ∑i=0∣In∣αi⋅ωi
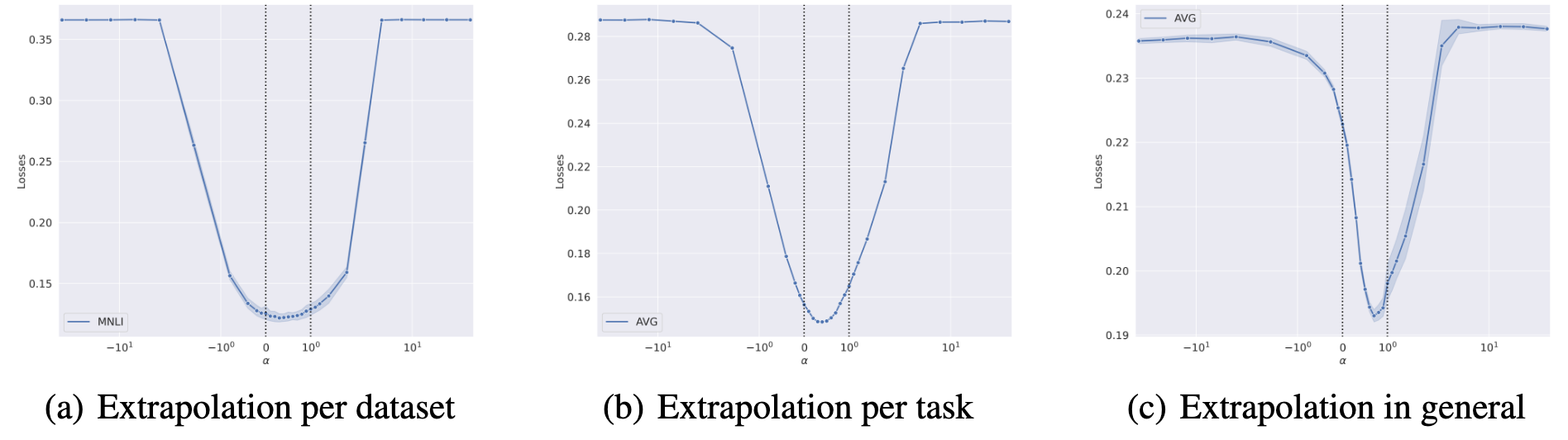
We now look for the boundaries of those regions, traversing in the opposite way to the interpolation.
check how far in the opposite directions (outside [0,1]) do we need to move in order for the loss to rise.