Background
- Languages allow us to encode abstractions, to generalize, to communicate plans, intentions, and requirements. These are fundamentally desirable capabilities of artificial agents.
- However, agents trained with RL and IL typically lack such capabilities, and struggle to efficiently learn from interactions with rich and diverse environments.
Using Natural Language for Reward Shaping in Reinforcement Learning (IJCAI 2019)

- A common approach to reduce interaction time with the environment is to use reward shaping.
- However, designing appropriate shaping rewards is known to be difficult as well as time-consuming.
- In this work, we address this problem by using natural language instructions to perform reward shaping.
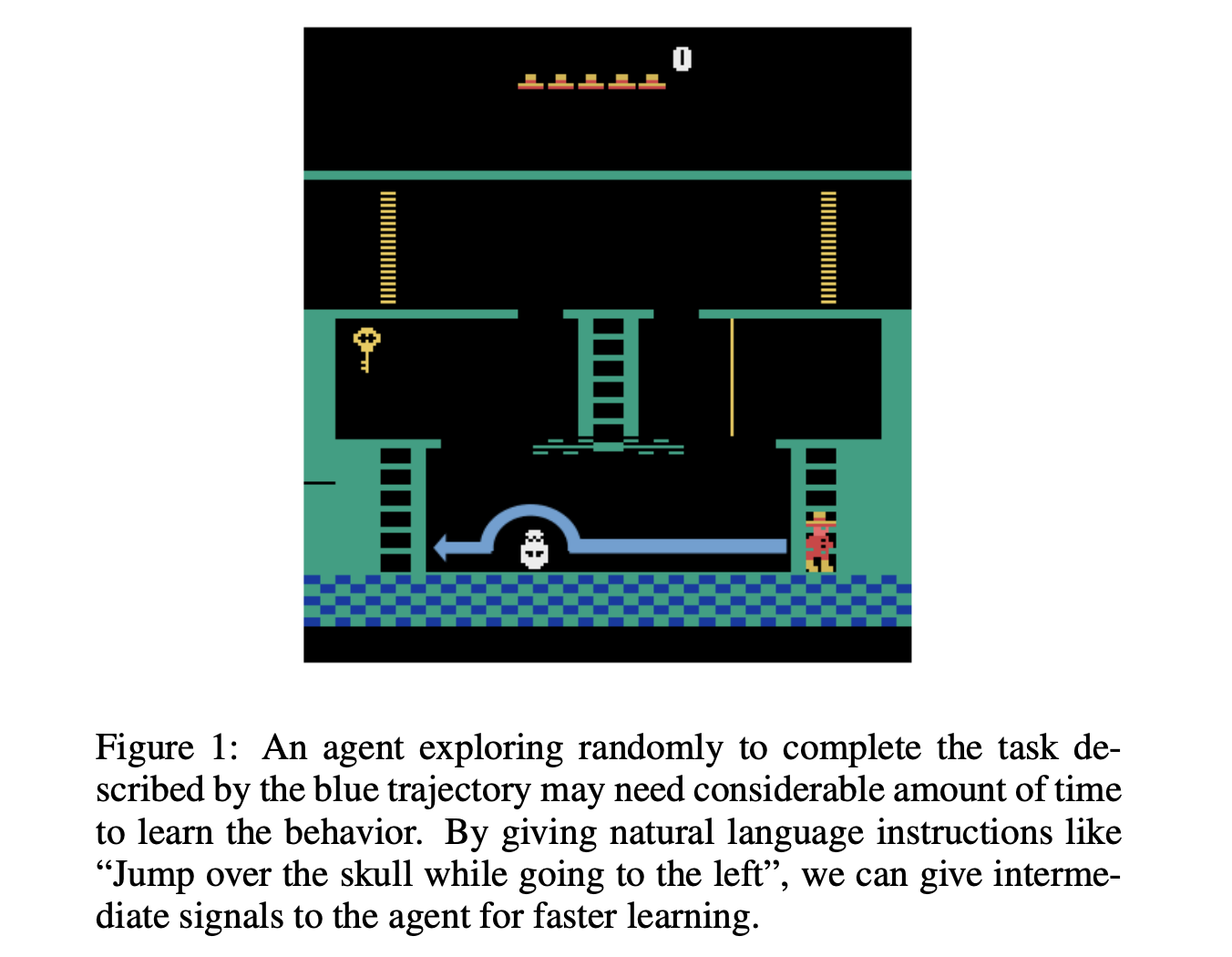
- If the agent is given a positive reward only when it reaches the end of the desired trajectory, it may need to spend a significant amount of time exploring the environment to learn that behavior.
- Giving the agent intermediate rewards for progress towards the goal can help (reward shaping). However, designing intermediate rewards is hard, particularly for non-experts.
- Since natural language instructions can easily be provided even by non-experts, it will enable them to teach RL agents new skills more conveniently.
Notations
- Consider an extension of the MDP framework, defined by .
- is a language command describing the intended behavior (with defined as the set of all possible language commands).
- We denote this language-augmented MDP as MDP+L.
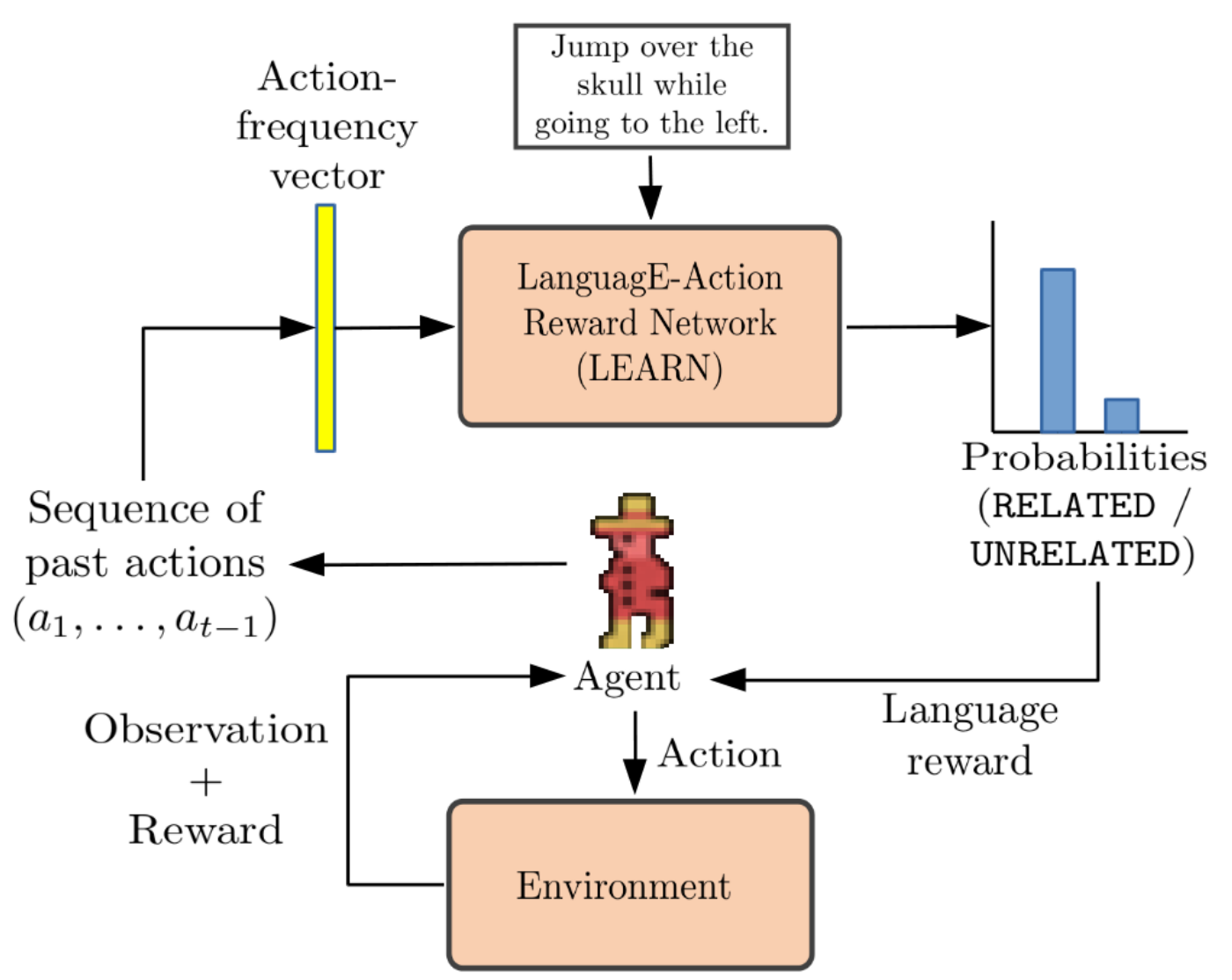
LanguagE-Action Reward Network (LEARN)
- Sample two distinct timesteps and from the set . Let denote the segment of between timesteps and .
- Create an action-frequency vector from the actions in . Create a dataset of pairs from a given set of pairs.
- Positive examples: created by sampling from a given trajectory and using the language description associated with .
- Negative examples: created by (1) sampling from , but choosing an alternate sampled uniformly at random from the data excluding , or (2) creating a random and pairing it with .

- The final output of the network is a probability distribution over two classes – RELATED and UNRELATED.
Language-based Rewards
- Given the sequence of actions and the language instruction associated with the given MDP+L, create an action-frequency vector .
- Let the output probabilities corresponding to classes RELATED and UNRELATED be denoted as and .
- Language-based shaping rewards:
- potential function:
- intermediate language-based reward:

Experiments
- Conducted experiments on the Atari game Montezuma’s Revenge. We selected this game because the rich set of objects and interactions allows for a wide variety of natural language descriptions.
- For each of the tasks, we generate a reference trajectory, and use Amazon Mechanical Turk to obtain 3 descriptions for the trajectory.

Summary
- 使用language description辅助reward shaping的出发点比较有趣,但是实现方法上过于生硬。
- action frequency vector并不是一个很好的设计/选择,e.g. (go leftgo downgo right) vs (go rightgo downgo left),从frequency角度来看这两个description是非常相似的,但实则产生的是截然不同的trajectory
- 文章claim的一个重点:natural language比expert knowledge容易获取,但是实验(task 14)中的失败说明了不够精确的natural language Instruction并不容易简单地被找到和action之间的关联,如果想要获得task 6中精准的Instruction,难度并不亚于expert knowledge。(不过可以考虑从NLP的一些语义解析方法出发来改进这一缺点)
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents

Background

Language Model
LMs are trained to fit a distribution over a text sequence via the chain rule:
Method
Plan Generation
To choose the best action plan among samples , each consisting of tokens , select the sample with highest mean log probability as follows:
Action Translation
Instead of developing a set of rules to transform the free-form text into admissible action steps, for each admissible environment action , we calculate its semantic distance to the predicted action phrase by cosine similarity:
where is an embedding function. (Translation LM)
Trajectory Correction
- Translating each step lacks consideration of achievability of individual steps.
- For each sample , we consider both its semantic soundness and its achievability in the environment.
We aim to find admissible environment action by modifying the ranking scheme:
Final Method

Experiments


Summary
- Language Model提供了优秀的联想能力,既能做到鼓励探索的发散型预测,也能在约束条件下提供高效完成目标的plan
- LM用于descion-making的优点在于能够充分地利用context信息(启发:在RL中同样不局限于Markov Property,尝试利用上更多的history?)
- 文章实验所使用的VirtualHome环境,action过于离散(开冰箱、取牛奶…)且space不大,也许一些常规的RL方法也一样可以学到好的policy,但文章的实验仅验证了其所生成的plan足以完成目标,但并没有定量评判和比较好坏程度。